
5 Best Large Language Models for Developers (2025)
As a software developer, you want a smooth coding experience to turn complex problems into clean, efficient solutions.
But let’s be honest: writing hundreds of lines of code is a difficult task, and even experts can run into errors and bugs.
This is where AI code tools make a real difference. They take care of the repetitive, basic tasks for you so you can spend your time on the bigger challenges like designing strong systems and building innovative features.
These tools are built on large language models (LLMs), which act like an AI coding assistant, helping you write entire functions, explain unfamiliar code, or even suggest better ways to structure your program.
But with every major tech company releasing its own AI, how do you choose the one that fits your specific tech stack, style, and budget?
We have done the hard work for you and analyzed the top contenders based on code accuracy, speed, integration, and value.
Read on to see our list of the best large language models and select the ideal AI partner for your development projects.
Let’s get started.
How Do LLMs Work?
A large language model is a highly sophisticated machine learning model and prediction engine used to generate human-like text.
They are trained on massive datasets to understand the patterns, structures, and nuances of human language, and they have a large number of parameters (in billions or trillions) to store what they learned from the data.
Modern LLMs are built on the transformer architecture that uses a self-attention mechanism to look at every word in a sentence and figure out the relationship between a sequence of words.
This allows the model to understand context and long-term dependencies, rather than just the previous word.
When you provide it with a prompt (an input sequence), it utilizes its self-attention capability to establish connections between all the words. Then, it uses everything it learned during training to calculate the probability of what word should logically come next.
It repeats this process, generating one word at a time, to create a complete and coherent response.
Key Features of Large Language Models
LLMs aren’t just chatbots. Here’s why they are useful:
- Text Generation: You provide a starting string, and the model generates context-relevant text to continue it. This is useful for writing emails, blog posts, generating synthetic data for testing, or code based on a prompt.
- Instruction Following: Instead of just completing text, you can give the model a direct command to make it more helpful and good at specific tasks, like being a chatbot assistant or a code generator. This is called fine-tuning the model. You give it examples of good responses and feedback, further training it to use its domain-specific knowledge to be useful and follow instructions.
- Question Answering: LLMs can answer questions based on the information they learned during training. However, it’s important to remember they can be factually wrong, so for precise data, they are best paired with a search system that provides them with up-to-date context.
- Text Summarization: They can digest large amounts of text and extract the key points concisely. This feature can help you make better decisions by providing you with the most essential facts from a long document or report.
- Code Generation: LLMs trained on code can generate code snippets from comments, translate code from one language to another, and explain what a complex piece of code does. They can also identify bugs, suggest fixes, and write unit tests.
- Multimodal Capability: Some LLMs accept other modalities in addition to text, such as code, images, audio, or video. This enables organizations to create applications that engage customers with augmented reality (AR) experiences or interactive multimedia content.
- Sentiment Analysis: You can ask the model to analyze text for emotions, such as positive, negative, or neutral.
snappify will help you to create
stunning presentations and videos.
5 Best Large Language Models
Here’s an overview of the best large language models for your development needs, including each tool’s features, pros, cons, and starting price.
GPT Series
OpenAI’s GPT series, which can be accessed via the ChatGPT chatbot, stands out as one of the most powerful LLMs for developers.
With comprehensive pre-training and deep contextual knowledge, GPT models excel at complex reasoning, tackling coding tasks, and fixing errors.
You can generate text and graphics from natural language descriptions, translate languages, solve programming tasks, and generate accurate code snippets.
Key Features:
- GPT-4o: It can generate text, audio, video, and images in real time. It also excels at multimodal tasks and rapid prototyping. It is the best option for building a real-time application, such as a voice assistant, customer support bot, or any other app that requires high-speed, low-cost API calls.
- GPT-4.1: It is more efficient than GPT-4o in processing speed, allowing faster response times and more refined responses. It focuses on advanced unsupervised learning with improved emotional intelligence (EQ), reduced hallucinations, and more natural conversational abilities. It is ideal for creative tasks and general-purpose applications, but lacks strong, complex reasoning.
- o3-mini and o4-mini: A cost-efficient, STEM-focused reasoning model designed for coding, math, and scientific tasks. It offers high accuracy and lower latency, making it ideal for technical domains.
- GPT-5: A unified intelligence system that dynamically balances fast responses and deep thinking for expert-level accuracy in coding, maths, and multimodal tasks. It significantly reduces hallucinations and has improved coding benchmarks compared to GPT-4. It is also useful for reasoning and debugging complex codebases, suggesting fixes, and summarising long diffs with fewer revisions.
Pros:
- Support for different frameworks and libraries.
- Integrated into a mature ecosystem (ChatGPT, API access).
Cons:
- Higher cost compared to smaller models.
- Limited customization for enterprise needs.
Pricing:
- Free plan available for basic use.
- Plus plan costs $20 per month.
Claude 4
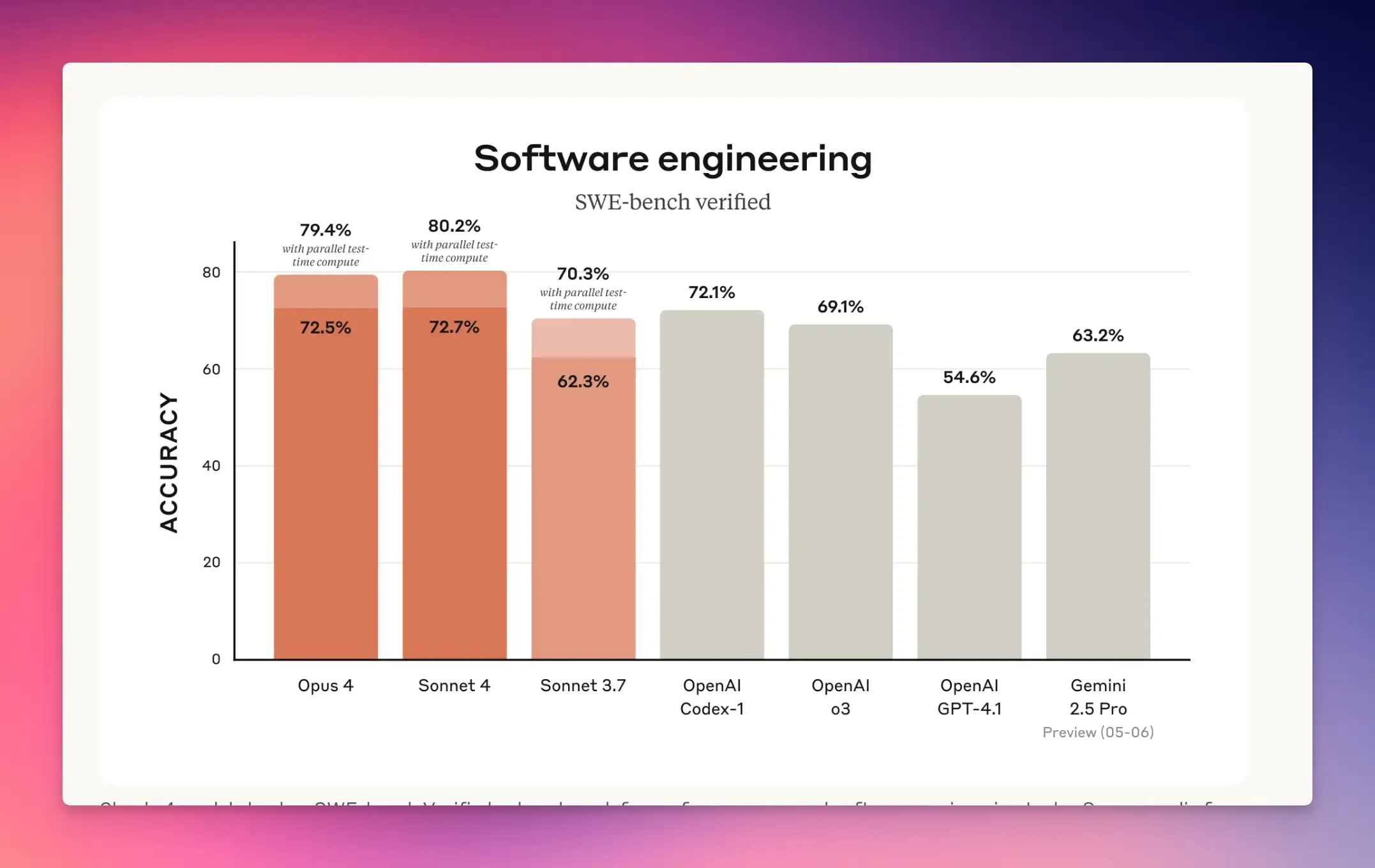
Anthropic’s Claude 4 series introduced two advanced models, Claude Sonnet 4 and Claude Opus 4, setting new benchmarks for coding and advanced reasoning.
These models represent significant advancements in agentic capabilities and are intended for serving various use cases based on complexity, cost, and performance requirements.
Claude Opus 4 excels in complex coding tasks, achieving 72.5% accuracy on SWE-bench (software engineering benchmark).
It can handle long-running tasks like refactoring large codebases for several hours without losing context.
Claude Sonnet 4 is optimized for high-volume coding tasks like code reviews, bug fixes, and feature development.
It scores 72.7% on SWE-bench and integrates with Claude Code for terminal-based development.
Key Features:
- Hybrid Reasoning: Both models provide near-instant responses for interactive tasks. Extended thinking mode enables step-by-step reasoning for complex problems, with visible thought processes.
- Large Context Window: They support a 200,000-token context window, allowing them to process extensive documents, codebases, or research data in a single prompt.
- Agentic Capabilities: Both models support tool use like web search and code execution, enabling autonomous AI agents for tasks like research, workflow orchestration, and multi-step problem-solving.
- Platform Access: Available via Anthropic API, Amazon Bedrock, and Google Vertex AI.
Pros:
- Ideal for coding and technical tasks.
- Good context retention.
Cons:
- Slower response times in extended thinking mode.
- Higher API costs for extensive usage.
Pricing:
- Pricing for Claude Opus 4 starts at $15 per million input tokens. Claude Sonnet 4 costs $3 per million input tokens.
- Claude Pro plan costs $20 per month (web/app access with extended thinking).
Gemini 2.5 Pro
Gemini 2.5 Pro is Google’s most advanced multimodal AI model with deep reasoning capabilities.
It is a great choice for developers and enterprises prioritizing complex reasoning, coding, and multimodal analysis.
Its massive context window and integration with Google’s ecosystem make it ideal for tasks like codebase debugging, research synthesis, and video-based app development.
For most use cases, it outperforms rivals like GPT-4.5 in reasoning and Claude 3.7 in multimodality, offering strong value through Google’s scalable APIs.
Key Features:
- Deep Think Reasoning Mode: Uses internal reasoning processes to improve accuracy for complex tasks like math, science, and coding.
- Context Window: Supports 1 million tokens, enabling analysis of entire codebases or long videos in a single prompt.
- Native Multimodality: Processes text, images, audio, video, code, and documents natively.
- Agentic Workflows: It supports code transformation, debugging, and generating executable applications from prompts.
- Google Ecosystem Integration: Available via Google AI Studio, Vertex AI, and Gemini Advanced subscriptions.
Pros:
- Excellent for research and data analysis.
- Strong performance in math and coding benchmarks.
Cons:
- Requires careful prompt engineering for optimal results.
- Higher latency in reasoning mode.
Pricing:
- Free version available in Google AI Studio.
- Google AI Pro costs $19.99 per month.
DeepSeek-V3.1

DeepSeek-V3.1 is the latest production-grade reasoning model by DeepSeek AI.
The model’s open-source availability, combined with its competitive pricing, makes it accessible to both individual developers and large organizations.
While it has some limitations in terms of hardware requirements and potential biases, its overall performance and flexibility make it an attractive option for developing modern AI applications.
Key Features:
- Hybrid Architecture: The model operates in two distinct modes: a non-thinking mode is optimized for speed and conversational use, providing immediate responses. Thinking mode activates advanced reasoning, multi-step planning, and agentic workflows for complex tasks.
- Context Window: It processes up to 128K tokens for analysis of large codebases.
- Mixture-of-Experts (MoE) Framework: It dynamically selects the most relevant “expert” models for a given task, improving both performance and efficiency.
- Advanced Tool Use and Agent Capabilities: Supports strict function calling for reliable API integration and enhanced post-training for multi-step agent tasks.
Pros:
- Cost-effective option for research and code generation across multiple programming languages.
- Open-source weights available on Hugging Face for self-hosting.
- Custom deployment options for enterprise use.
Cons:
- Requires technical expertise for deployment.
- Smaller community compared to established models.
Pricing:
- Available for free via Deepseek chat.
- API pricing for a million input tokens is $0.56 (cache miss) and $0.07 (cache hit).
Grok Code Fast 1
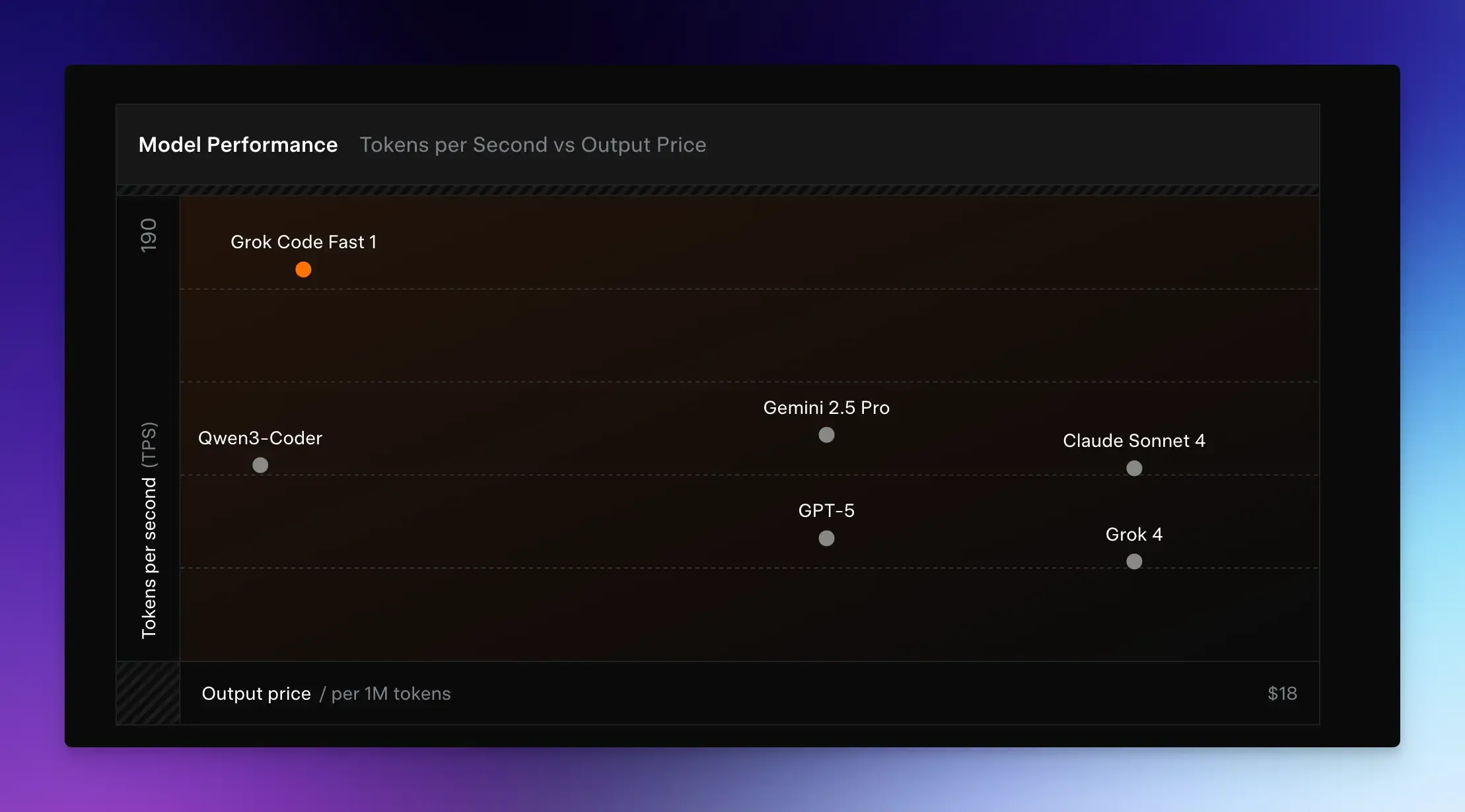
Grok Code Fast 1 is a specialized LLM developed by xAI for agentic coding tasks.
It acts as a dedicated coding assistant, prioritizing speed, cost efficiency, and easy integration with developer tools such as IDEs and terminals.
Unlike Grok-4, which is a general-purpose model, Grok Code Fast is specifically optimized for tasks such as code generation, debugging, and tool-based operations, including terminal commands and file edits.
Key Features:
- MoE Design: It uses specialized experts for different coding tasks, balancing capability and speed.
- 256K Token Context Window: Handles large codebases, lengthy logs, and multi-file projects without losing coherence.
- Tool Integration: Natively supports commands, terminal operations, and file editing for autonomous code execution and debugging.
- Visible Reasoning: Shows step-by-step thinking during problem-solving.
- Language Support: Works with TypeScript, Python, Java, Rust, C++, and Go.
Pros:
- Strong performance in rapid prototyping, bug fixes, and code refactoring.
- Works with Cursor, GitHub Copilot, Cline, and Windsurf.
Cons:
- Lags in complex reasoning compared to GPT-5 or Claude Sonnet 4.
- Lacks multimodal capabilities.
Pricing:
- Available for free via GitHub Copilot, Cursor, and Cline.
- It costs $0.20 per million input tokens.
Other Popular LLMs to Consider
- Qwen 3 (Alibaba): A versatile open-source model offering thinking/non-thinking reasoning modes. Strong multi-lingual support, good reasoning, and code generation.
- Llama 4 Scout (Meta): Highly efficient multimodal model with a 10 million token context window, ideal for processing long documents and codebases.
- Mistral AI: Open-source models offering multi-lingual reasoning and cost-efficient deployment.
- Falcon Series: Falcon-H1 models use a hybrid attention-state space model (SSM) architecture for efficient long-context processing. They lead in open-source performance for STEM and multi-lingual tasks.
snappify will help you to create
stunning presentations and videos.
Final Words
There are numerous powerful large language models to choose from.
You can find a tool that fits your needs and budget, whether you want a fast coding assistant, an analytical model, or an open-source option.
These AI partners help you write better code, solve problems faster, and focus on the creative parts of development, making it easier to bring your ideas to life.
If you like this article, don’t forget to check out:
FAQs:
How do I choose the right model for my project?
If you need speed and low cost for routine coding, try Grok Code Fast 1. For complex reasoning or research tasks, Claude 4 Sonnet or GPT models are better choices.
Can I use these models on my own servers?
Open-source models like Llama 4 Scout, DeepSeek-V3, and Falcon can be self-hosted on your own hardware or private cloud, giving you full control over data and usage.
