
SKIP N ROWS
reading csv in databricks

Did you know you can easily skip N rows of a CSV file in Databricks? 🤔
Unfortunately, PySpark lacks the ability to skip rows directly, so we need to use the underlying RDD syntax and filter the rows. This is not very user-friendly for such a basic operation!
+-----------------------+--------------------+
|This row is unnecessary| and you can skip it|
+-----------------------+--------------------+
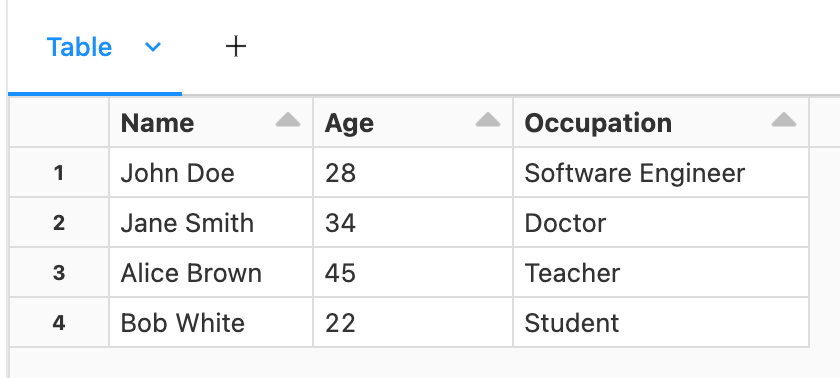
| Name| Age|
| John Doe| 28|
| Jane Smith| 34|
| Alice Brown| 45|
| Bob White| 22|
+-----------------------+--------------------+skiprows.csv
This row is unnecessary, and you can skip it
Name, Age, Occupation
John Doe, 28, Software Engineer
Jane Smith, 34, Doctor
Alice Brown, 45, Teacher
Bob White, 22, Studentskip = (
spark.read.format('csv')
.option("inferSchema", True)
.option("header", False)
.option('sep', '|')
.option('skipRows', 1)
.load('skiprows.csv')
)
display(skip)Incorrect output in spark 2.4.1
🪄✨
Use the `skipRows` option
Databricks skips first header!